
Primeiros Passos com Spark!
Hoje irei falar e demonstra um pouco a respeito do Spark, usando pyspark para analise de dados!
Antes de Começarmos
Bom precisamos entender melhor o que é o Spark, antes de entrarmos na fase mais legal que é onde codamos…
- O Spark não é mais do que uma plataforma de computação de cluster de uso geral e rápida. Em outras palavras, é um mecanismo de processamento de dados de código aberto e ampla escala. Foi pensado para se trabalhar com Big Data.
- Oferece processamento de fluxo em tempo real, processamento interativo, processamento de gráficos, processamento na memória, bem como processamento em lote, com velocidade muito rápida, facilidade de uso e padrão de interface.
- Existem alguns componentes que fazem parte do Apache Spark, sendo eles: Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark GraphX, SparkR
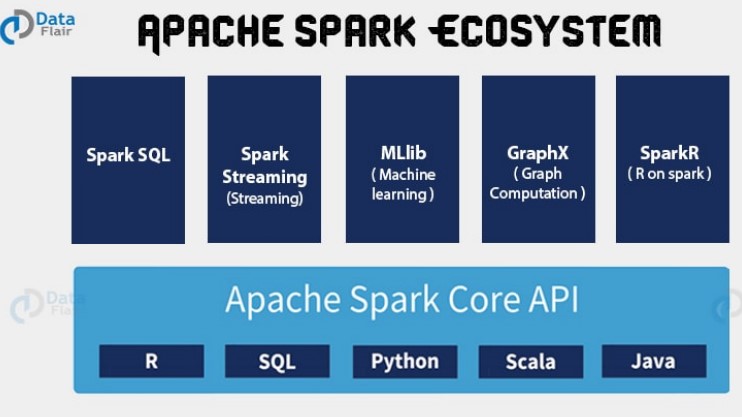
Dentro do ecosistema do Spark, temos os chamados RDDs (Resilient Distributed Dataset), que é considerada a unidade fundamental de dados dentro do Spark, é uma coleção distribuída de elementos nos nós do cluster(hadoop). Também executa operações paralelas. Além disso, os Spark RDDs são imutáveis por natureza. Embora possa se gerar um novo RDD transformando um Spark RDD existente.
Ou seja, de forma a abstrair melhor, é como se o RDD fosse um arquivo de excel, mas que só pode ser manuseado por uma ferramenta especifica, e que tem uma natureza imutável, e para fazer análises nos dados que estão armazenados num RDD é preciso efetuar uma das duas ações possíveis dentro dessa estrutura de dados, que são as Operações de Transformação e Operações de Ação.
É bom lembrar que os dados dentro do RDD agem como um dicionário em Python, onde temos Chaves e Valores.
- Operações de Transformação
- groupByKey — Agrupa todos os valores com a mesma chave.
- reduceByKey(fun) — a operação reduceByKey geralmente combina valores com a mesma chave.
- keys() — Geralmente retorna um spark RDD apenas com as chaves.
- values() — Geralmente retorna um spark RDD apenas com os valores.
- sortByKey() — Retorna os valores do RDD classificados pela chave.
- Operações de Ação
- collectAsMap() — Aqui, a operação collectAsMap () ajuda a coletar o resultado como um mapa para fornecer uma consulta fácil.
- countByKey() — Através da operação countByKey, podemos contar o número de elementos para cada chave.
- lookup(key) — Ele retorna todos os valores associados à chave fornecida.
Iniciando as Análises
Bom, provavelmente você está se perguntando, como iremos utilizar o Spark, já que ele é utilizado com um cluster, normalmente associado ao Hadoop, para contornar essa questão iremos usar o Databricks, que possibilita utilizarmos uma máquina virtual, bastando criar uma conta de comunidade (é possível instalar o Spark na sua máquina, mas irá utilizar os recursos do seu computador para processar os dados)
- Vá até ao Databircks (https://databricks.com/try-databricks)
- Faça o cadastro na Edição da Comunidade.
- É importante se lembrar que após o cadastro, quando for efetuar o Login, clicar na parte inferior onde diz algo do tipo “Login para cadastro da edição de comunidade”
- Assim que entrar no painel do Databricks, você terá acesso a inúmeras opções, para iniciar seu notebook de analises basta clicar em “New Notebook”
- Caso esteja acostumado com Python, o que irá ver é uma especie de Jupyter Notebook, o funcionamento é o mesmo, é possível utilizar o Spark com diferentes linguagens, aqui iremos utilizar o pySpark, ou seja o código remete aquilo que já estamos acostumados ao programar em Pythons.
- Iremos utilizar para esse trabalho um dataset do Kaggle, que pode ser baixado aqui: https://www.kaggle.com/carrie1/ecommerce-data para fazer o uso, é interessante subir o arquivo CSV em algum link, como o dropbox por exemplo =)
Código
Importanto tudo que precisamos.
import pyspark
from pyspark.sql.types import *
from pyspark.sql import Row
import pyspark.sql.functions as func
from pyspark.sql import SparkSession
from pyspark.sql.functions import unix_timestamp
from pyspark.sql.functions import from_unixtime
from pyspark.sql.functions import year, month, dayofmonth, hour, minute, concat_ws, date_format
Importanto os dados
%sh wget https://meudropbox/blabla/dataset.csv
df = spark.read.option("sep",",").option("header","true").option("inferSchema","true").csv("file:/databricks/driver/dataset.csv")
Resaltamos aqui, que o uso de DataFrame no Spark é algo comum, embora seja possível criar um RDD a partir dos dados em CSV, podemos fazer toda análise tendo como base um DataFrame, como os DataFrames em Pandas no Python.
1 - Percebemos que a coluna CustomerID e Description tem valores em falta, começamos por descartar todos os registros que tem valores em falta em uma ou mais colunas.
removeAllna = df.na.drop()
removeAllna.describe(['CustomerID']).show()
removeAllna.count()
display(removeAllna)
2 - Descarte todas as linhas onde o valor de Quantity seja um número negativo. Para isso utilizamos o que seria uma Operação de Transformação em um RDD, filter ou como demonstrado abaixo o where.
removeNegativedf = removeAllna.where("Quantity>0")
display(removeNegativedf)
3 - Crie uma nova coluna que corresponda ao valor gasto por registro.
removeNegativedf = removeNegativedf.withColumn('amount_spent', func.round(removeNegativedf.Quantity * removeNegativedf.UnitPrice, 2))
4 - Colete os dados do invoice_date e crie outras colunas: year_month, month, weekday, day, hour.
removeNegativedf = removeNegativedf.withColumn('Date', from_unixtime(unix_timestamp('InvoiceDate', 'MM/dd/yyyy HH:mm')))
removeNegativedf = removeNegativedf.withColumn("year_month", concat_ws("",year("Date"),month("Date")))
removeNegativedf = removeNegativedf.withColumn("month", month("Date"))
removeNegativedf = removeNegativedf.withColumn("weekday", date_format("Date","E"))
removeNegativedf = removeNegativedf.withColumn("day", dayofmonth("Date"))
removeNegativedf = removeNegativedf.withColumn("hour", hour("Date"))
5 - Quais são os top 5 clientes com o maior número de encomendas (número de invoices diferentes). Repare que a partir desse ponto os dados que são apresentados e o próprio código, lembram bastante SQL.
removeNegativedf.groupBy('CustomerID').count().sort('count', ascending = 0).show(5)
6 - Quais são os top 5 clientes que que gastaram mais dinheiro de acordo com os dados.
removeNegativedf.groupby("CustomerID").agg(func.sum("amount_spent").alias("amount_spent"
)).sort("amount_spent", ascending=0).show(5)
7 - Qual o número total de encomendas por mês. (temos que ter em atenção aqui o .countDistinct, que funciona no DataFrame dentro do Spark, se fosse com Pandas em Python, o código seria um pouco diferente e em SQL usariamos o Distinct mas de uma forma também diferente)
removeNegativedf.groupby("month").agg(func.countDistinct("InvoiceNo")).sort("month", as
cending=1).show()
8 - Qual o número de encomendas por dia da semana.
removeNegativedf.groupby("weekday").agg(func.countDistinct("InvoiceNo")).sort("weekday"
, ascending=0).show()
9 - Qual o número de encomendas por hora.
removeNegativedf.groupby("hour").agg(func.countDistinct("InvoiceNo")).sort("hour", asce
nding=1).show()
10 - Qual o valor da encomenda mais cara por hora. (embora retorne um resultado, aqui existe alguma incerteza a respeito de estar totalmente correto)
removeNegativedf.groupby("hour").max("amount_spent").sort("hour", ascending=1).show()
11 - Quais os 20 países com mais encomendas.
removeNegativedf.groupby("Country").count().sort("count", ascending=0).show(20)
12 - Qual a média de gastos por cliente em cada País.
removeNegativedf.groupby("Country").agg(func.avg("amount_spent").alias("total spent")).so
rt("total spent", ascending=0).show()
13 - Qual a média do número de itens por fatura/encomenda.
removeNegativedf.groupby("InvoiceNo").agg(func.sum("Quantity")/func.count("Quantity")).show
()
14 - Quais são as palavras mais comuns na coluna Description. Temos aqui um variação interessante, uma vez que a partir do DataFrame, seria complicado chegar ao resultado esperado, utiliza-se então uma TempView, que transforma temporáriamente os dados em um banco de dados, sendo possível usar queries SQL.
removeNegativedf.createOrReplaceTempView("finalDF")
wCount = spark.sql("SELECT word, count(*) AS count FROM (SELECT explode(split(Descripti
on, '\s')) AS word FROM finalDF) w GROUP BY word")
wCount.sort("count", ascending=0).show()
Temos assim uma análise simples ao dados de um CSV com cerca de 500 mil linhas, algo que sem o uso do Spark poderia gerar alguma dor de cabeça, embora o Spark em si seja algo mais amplo, de forma simples e direta consguimos ver seu potencial, existem alguns fatores importantes que não mencionei, como é o caso do Spark Context, ou de todas as outras Operações de transformação e ação, deixo assim que a curiosidade dos interessados levem a pesquisas mais aprofundadas =)